November 26th, 2011 by reynman
Now that my food coma is wearing off, I thought this would be a good time to go back and look at how the algorithm fared for the 2011 season. If we look at every bout from the end of Championships 2010 until the end of Championships 2011 (601 bouts in all), the algorithm correctly picked the winner in 491 of them (81.70%). This was slightly worse than our 85.1% from the 2010 season. However, given that we used the data from 2010 to train the algorithm, it would be unreasonable to expect the same result.
One of the effects that elicited several comments was the impact of new teams. Since we chose to assign a rating of 600 to any previously unranked team, some rather unfair alterations in the ratings of their first few opponents would result. And, while it's true that the proper ratings would eventually be restored after a few more bouts, it seems reasonable that those ripples reduced the overall effectiveness of the algorithm. Out of simple curiosity, I excluded any bout in which a completely new team participated. That reduced the total sample to 570 bouts, of which the algorithm correctly predicted 466 (81.75%). Clearly, the new bouts didn't really affect the overall accuracy.
In fact, our worst performance was from the final post-season tournaments. In those 80 bouts, the algorithm only correctly predicted 61 winners (76.25%) – special recognition has to go to London who had the largest number of post-season prediction upsets at 3. I'm not too worried about this, since it reflects the rather long layoff between regular season play and the post-season tournaments. After all, with more than a month in between, a lot can change in the skills and strategies of teams going to the post-season tournaments.
Of course, wins and losses are only the simplest way of judging the algorithm. What's actually more critical is how close the algorithm came in predicting the score – or more accurately the DoS – of the bout. In the following plot, I compare the actual result of each of the 601 bouts with the respective prediction from the algorithm.
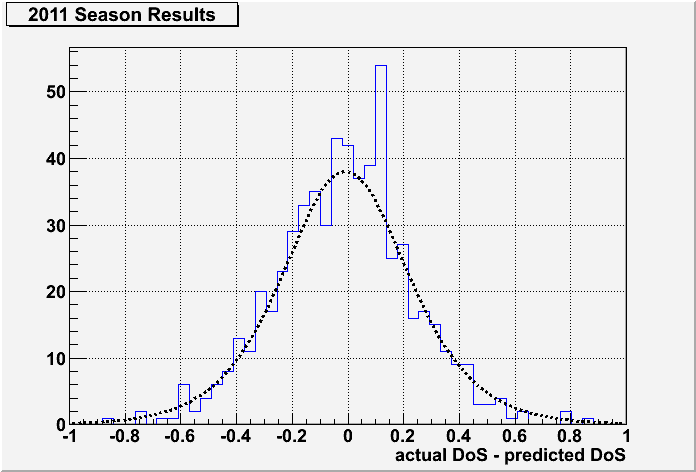
The x-axis shows the difference between the actual result and the prediction, from the perspective of the home team. A positive value means that the home team performed better than predicted and a negative value means that the home team performed worse. Of course a zero means that the prediction was exactly right. The height of each bar shows the number of bouts that had that result. The fact that most of the bouts are between -0.2 and +0.2 shows that the algorithm was doing a pretty good job over the season. Of course, the algorithm is not expected to be a perfect predictor. Some statistical variation is expected. The dashed line actually shows the same distribution from all the previous bouts that were used to train the algorithm – that would be all bouts from 2005 through 2010 Championships. Only the height of the curve was scaled to match the number of bouts in 2011. It fits the data quite well – for those who geek out on this sort of thing, a chi-squared test gives a 75% probability that these two are describing the same distribution.
So where do we go from here? I think the overall performance of the algorithm has been very robust during it's first year, so I don't think there's any reason to change the fundamental structure. However, reducing the ripples caused by the introduction of new teams will likely improve the overall performance. A very good suggestion was made by bjmacke earlier this year that greatly reduces this effect by using a team's first game to set their initial rating (and not changing the rating of the opponent). It turns out that re-optimizing the algorithm with this simple change not only improves the overall accuracy, but also greatly reduces some of the non-intuitive biases that we had previously found, such as the home/away bias in post-season tournaments. I'm currently finalizing the optimizations and I expect that we'll roll out the upgrade somewhere around the beginning of the year. When that happens, you'll see the ratings shift around a little bit, so don't get freaked out if your team's rating drops by 50 points....everybody else will get shifted too.

Comments
I'm so pleased to hear of the upcoming adjustments, particularly the home/away bias in the big five tournaments. Yay for intuitiveness. Please make a big announcement when the change happens so I can minimize my freaking out.
Waiting anxiously.
(Why does it take so long? ;)
If a team's first game will set their initial rating, what would the algorithm do if both teams are playing their first official game? It's unlikely something like this would happen, but perhaps maybe the initial ranking could also factor in any unofficial games while a team was still under apprentice status as well?
Yes, that was/is the difficult part in putting together the new algorithm...which is why it's taken so long. As a matter of fact, in the history of WFTDA, two new teams have played each other for their first official bout 15 times (twice in 2011). I was even further disturbed this year to see the games between Des Moines and Babe City -- they played two bouts against each other before scheduling bouts agains other veteran teams.
I'm not inclined to use unofficial games as part of the "official" ranking. So many random things can be different in an unofficial game. Rather, I've been able to find a way to start these ratings in a position relative to the overall distribution of all teams. It's not perfect, but it doesn't cause too much disruption...and as long as we only have a few of these bouts, it's better than the previous system.
Sounds good. Just to clarify my original post, I wasn't suggesting using unofficial games as a part of the ranking, but instead to give a more realistic idea as to where someone stands as an apprentice league before they take on official games. You're absolutely right that these games can be affected by random things that wouldn't happen in an official game (such as a team not bringing their full roster/bringing a B-team skater to season them up since it's not sanctioned or what have you).
Looking forward to see how the new algorithm ranks people! Thanks for all the hard work.
In rereading this post, I've come to a new appreciation of it, now that I've developed my own Elo system. It seems to me that nothing has changed. Your system has an accuracy of about 80% for 'regular season' and 75% for 'tournament season'. My system is the same. Any ideas as to why that would be true? And what's your evaluation of your two unranked teams play each other and each get a ranking?
As usual I seem to be a year behind,
Southbay